ALL(*) lookahead in Langium
 Mark Sujew
Mark SujewThe original paper about the ALL(*) lookahead has been released in 2014. Even though it features the most powerful LL-style lookahead algorithm to date, it has found little adoption outside of ANTLR4. I am proud to announce that Chevrotain and by extension Langium now support the ALL(*) lookahead algorithm through the Chevrotain Allstar package.
In this article I want to explain why we went with the Chevrotain parser library instead of ANTLR4 for Langium in the first place and how we ported the ALL(*) lookahead to Chevrotain.
By the way, if you’re wondering why there’s a tiny deer in the blog overview: It’s a chevrotain!
Why Chevrotain?
When the question about the underlying parser library for Langium came up back in February of 2021, the answer wasn’t very clear. Coming from Xtext, our team at TypeFox had quite a smooth ride with ANTLR3. Its successor, ANTLR4 was an instant candidate for Langium. Its lookahead algorithm is more advanced than ANTLR3’s LL(*) in two major aspects. For one, it is capable of incorporating rule recursion into the lookahead. Also, it handles direct left recursion without the need to refactor the grammar. Of course, the whole LL(*) aspect of ANTLR3/4 was very enticing from the get-go. Having unbounded lookahead makes intuitive grammar design much more feasible. Refactoring parts of your grammar just because your parser isn’t powerful enough is always a pain and is usually to the detriment of both grammar readability and AST navigation.
So with all that in favor of ANTLR4, what spoke against it? Well, we wanted to make developing a language with Langium as straightforward and simple as possible. Unfortunately, compiling ANTLR grammars requires the ANTLR dev tools, which are written in Java. While the runtime itself would be pure JavaScript, every developer using Langium would be required to install a Java runtime. So this was an obvious hurdle in adopting ANTLR for Langium.
We started researching for other parser libraries and were happy to see that basically everything else that was available either didn’t require a separate compile step or had its dev tools written in JavaScript. Something which immediately stood out was that in every performance comparison, Chevrotain outperformed basically everything else by multiple factors. Even handwritten parsers! In addition, it featured sophisticated ANTLR-style error recovery, which I’ve found to be lacking in the JS parser library space - most of them just stop parsing once they encounter an error. Even more fascinating was that Chevrotain didn’t even require a compilation phase. You just write your parser in code and when instantiating the parser, it will initialize itself within a few milliseconds.
Even though it was just an LL(k) parser, Chevrotain had so many advantages compared to ANTLR4 that it quickly became the parser of choice for Langium. Now, Chevrotain wasn’t perfect for our use case yet, but we were quite sure that we could get it there. Maintenance on Chevrotain is still very much active, and the library is becoming more and more popular. With that in mind, we decided to make it the underlying parser engine for Langium.
Unexpected advantages
Even though we didn’t know it at the time, Chevrotain offered us to build an impressive dev- and showcase-tool. Initially, we just generated a Chevrotain parser based off of Langium grammars to a TypeScript file that needed to be compiled first. This was handy for multiple reasons, the most important being that it made our parsers very easy to debug. Something which was crucial while figuring out how to generically parse an abstract syntax tree from a DSL file. However, as Langium’s parser infrastructure became more and more stable, this became less relevant.
The interpreted approach of Chevrotain enabled us to create a parser in-memory from a grammar description without any intermediate representations needed. We took this opportunity and implemented full in-memory parsers for version 0.2 of Langium back in fall of 2021. An immediate advantage of this approach was that we could test parsing features of Langium easily in any configuration without creating a whole Langium project for that. We could just parse a Langium grammar and create a testable parser for it. Continuing this train of thought eventually led us to the Langium Playground, our most impressive showcase yet for the Langium project as a whole.
Introduction to LL lookahead
I’ve previously talked about LL(k) and ALL(*) parsers, but what does that even mean?
When building a parser, you will eventually need to decide which path to take through your input. For example, to decide whether what you read is a function or class.
We call this process lookahead, because it looks ahead into the input to determine which path we need to choose.
In the example this is simple, because we probably just look for a function or class keyword.
However, with arbitrary grammars comes arbitrary complexity.
We express this complexity with the amount k of tokens that our lookahead algorithm needs to peek into the input.
The LL part stands to Left-to-right, Leftmost derivation. This is the most common type of parser that you encounter. ALL(*) (read All-Star) is just a funny acronym for adaptive LL(*) with the * symbolizing a potentially unlimited amount of lookahead. This potential unlimited amount of lookahead has a major technical implication. There are a lot of grammars which we simply cannot parse with LL(k) (even with a large k) that might seem trivial at first. Take the following EBNF grammar:
A ::= a* b | a* c
The language this grammar produces is basically just a arbitrarily long list of a followed by either a b or c. Easy, right?
Unfortunately, LL(k) parsers are unable to distinguish between these alternatives, as the potential length of any alternative prefix must be known statically for LL(k) parsers.
From LL(k) to ALL(*)
We still had the problem that Chevrotain was only capable of parsing LL(k) languages, meaning that examples such as the one above simply yield a parser initialization error. This is where my work of the past year comes into play. Over the course of 2020 and 2021, I was in the process of pursuing a master’s degree in computer science and had to write my thesis at the end of 2021. And what better topic to pick than applying the (relatively) novel ALL(*) algorithm to another library and performing an extensive performance review? So I got to work…
At the end of April 2022 I had a working version of Chevrotain which included the ALL(*) lookahead algorithm. But why did this take almost half a year? Well, let’s talk about how the ALL(*) algorithm works:
From static…
LL(k) parsers work by first constructing a large 3-dimensional array for each decision point in a grammar. This array basically contains all possible paths through all decisions and depending on which bucket the input falls into, we choose a specific alternative. As mentioned before, this requires a lot of computation on statically known information. Once we lose this information, this method ceases to work.
Instead, we transform each rule of our grammar into an augmented transitioning network (ATN). This is effectively a nondeterministic finite automaton (NFA) that allows us to simulate each rule of our grammar. It looks similar to syntax documentation graphs for popular languages:
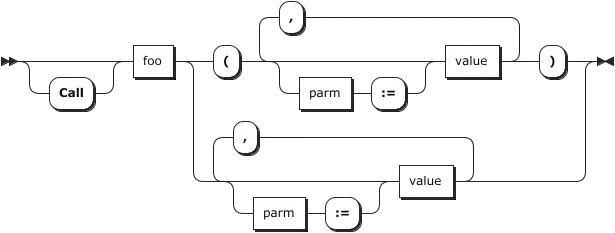
…to dynamic
As far as the static part is concerned, we are done. The heavy lifting is now being performed during the parser runtime. Each time we encounter a decision point while parsing, we first take a look at its respective ATN state. Starting from this ATN state, we construct a new deterministic finite automaton (DFA) for this decision point. For each token, we iteratively apply the subset construction algorithm on our ATN until only one possible alternative remains.
This is obviously quite slow compared to just looking up a sequence of tokens in an array. We can make it faster though, by storing each intermediate step as a DFA state and link it using the encountered token. Whenever we encounter the same token for the same decision, we don’t invoke the subset construction algorithm but will instead just look up the already existing DFA state that is linked to this token type. This massively reduces the complexity of our lookahead algorithm from O(n4) to O(n). The memorization approach is inspired by the PEG/Packrat parser system.
Performance results
The results reported for the introduction of the ALL(*) algorithm hinted at increased parsing speed compared to the more traditional LL approaches. While migrating Chevrotain to ALL(*) we could compare directly how the algorithm fairs against its original version. What I’ve found was that the algorithm yields slightly worse results (less than 5% worse) for commonly used grammars. Additionally, it requires a bit of memory, since we memorize previous parsing decisions. This was not necessary for the LL(k) lookahead. However, that is a price we’ll gladly pay for a massive increase in power.
A compromise
The original pull request for introducing ALL(*) to Chevrotain contained more than 4.000 changed lines of code. Merging such a large change could have unforeseen negative consequences for existing adopters. So instead of making ALL(*) the default lookahead, we opted to go down a different route. Instead of changing the way all Chevrotain parsers work, we make the lookahead pluggable and release a ALL(*) lookahead plugin that users can use if they want to.
And that’s exactly what we did. With Chevrotain version 10.4.1 the pluggable lookahead API was introduced and we wrote our package against that. We are currently testing the implementation for Langium and it will be generally available starting with the next official release of Langium.
Conclusion
Making the ALL(*) algorithm available for Chevrotain was quite a lot of work, but I believe it was all worth it at the end. Especially since I got a cool master’s thesis out of it. If you want to take a closer look at it, you can read the full thesis here.
As always, if you’re interested in this kind of work, consider joining TypeFox. We’re hiring!
About the Author
Mark Sujew
Mark is the driving force behind a lot of TypeFox’s open-source engagement. He leads the development of the Eclipse Langium and Theia IDE projects. Away from his day job, he enjoys bartending and music, is an avid Dungeons & Dragons player, and works as a computer science lecturer at a Hamburg University.



